
Anthropic vient de frapper un grand coup dans la course à l’intelligence artificielle. Le 17 février 2026, l’entreprise a lancé Claude Sonnet 4.6, une mise à jour de son modèle intermédiaire qui bouscule toutes les hiérarchies établies. Le plus remarquable dans cette annonce n’est pas tant les performances brutes du modèle, mais le fait qu’il soit accessible gratuitement à tous les utilisateurs, y compris ceux sur l’offre standard.
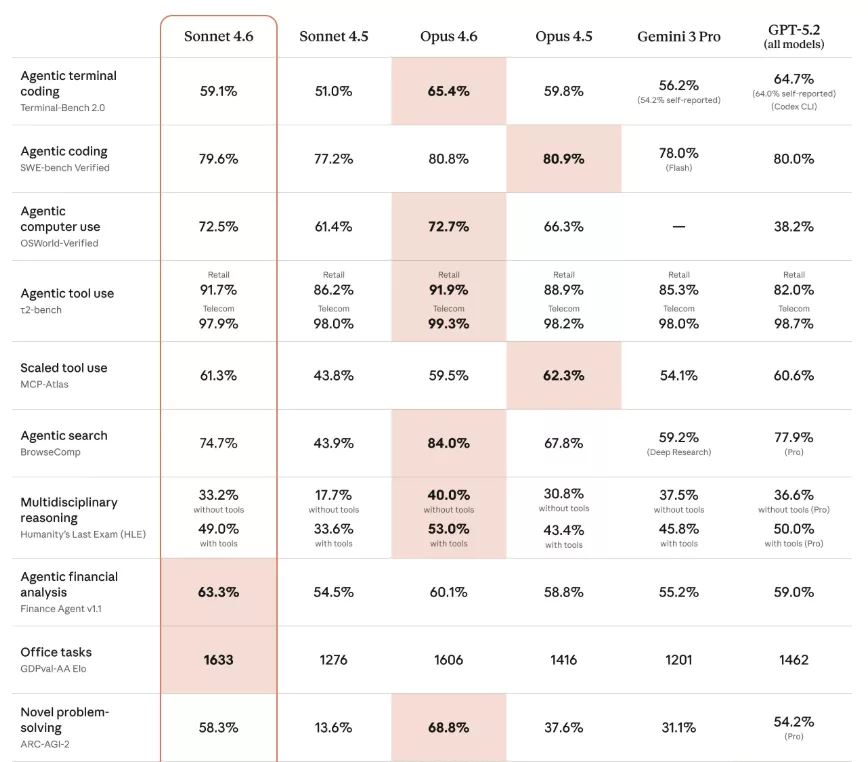
Avec un score de 79,6% au SWE-bench et 72,5% sur OSWorld, Sonnet 4.6 talonne directement Opus 4.6, le modèle premium d’Anthropic, sur les benchmarks qui comptent le plus pour les développeurs. Une fenêtre de contexte d’un million de tokens vient compléter le tableau. Voici pourquoi cette sortie redistribue les cartes.
Claude Sonnet 4.6 : un modèle gratuit au niveau des meilleurs
Pour comprendre l’impact de cette sortie, il faut d’abord situer Sonnet dans la gamme d’Anthropic. L’entreprise propose trois niveaux de modèles : Haiku, le plus léger, conçu pour les tâches simples et les scripts basiques ; Sonnet, le modèle polyvalent du quotidien ; et Opus, le cerveau ultime, réservé aux tâches de raisonnement avancé et de codage intensif.
Jusqu’à présent, accéder aux performances les plus élevées nécessitait un abonnement Pro ou Max, dont les tarifs montent rapidement. Avec Sonnet 4.6, Anthropic rend accessible gratuitement un modèle dont les capacités s’approchent de celles d’Opus sur de nombreux critères. La fenêtre de contexte passe à 1 million de tokens, une capacité qui était jusqu’ici réservée exclusivement à Opus pour les abonnés payants.
Côté API, les tarifs restent inchangés par rapport à Sonnet 4.5 : 3 dollars par million de tokens en entrée et 15 dollars en sortie. Pour les développeurs qui utilisent l’API, cela représente un rapport qualité-prix particulièrement agressif.
Des benchmarks de codage qui talonnent Opus
Le benchmark le plus surveillé par les développeurs est le SWE-bench Verified, qui soumet les modèles à de vrais problèmes GitHub à résoudre. Sonnet 4.6 y obtient un score de 79,6%, à seulement un ou deux points d’Opus 4.6. Pour un modèle accessible gratuitement, c’est un résultat remarquable qui place Sonnet dans la cour des grands.
Sur le benchmark OSWorld (Computer Use), qui mesure la capacité d’un agent IA à naviguer sur un ordinateur comme un humain, Sonnet 4.6 atteint 72,5%. C’est une progression significative par rapport aux 61,4% de Sonnet 4.5, et ce score dépasse même les 66,3% d’Opus 4.5. En à peine 15 mois, les scores sur ce benchmark sont passés de 14% à plus de 72%, une accélération spectaculaire.
En tests internes sur Claude Code, les développeurs ont préféré Sonnet 4.6 à Sonnet 4.5 dans 70% des cas, et même à l’ancien modèle phare Opus 4.5 dans 59% des cas. Sur le terminal bench CLI, Sonnet 4.6 prend même une légère avance sur Opus 4.6.

Performances bureautiques et raisonnement stratégique
Au-delà du codage, Sonnet 4.6 brille également sur les tâches bureautiques. Le benchmark GDPval mesure la capacité d’un modèle à gérer des graphiques, des PDF, des tableaux et à extraire des données, bref, tout ce que fait un consultant bien payé au quotidien. Ce benchmark attribue un score ELO, comparable à celui utilisé aux échecs.
Sur le leaderboard GDPval AAA, Sonnet 4.6 obtient un score de 1603 points, ce qui en fait l’un des modèles les plus performants sur ce type de tâches. En mode adaptive reasoning (raisonnement adaptatif max effort), Sonnet 4.6 se place même devant Opus 4.6 sur certaines métriques. C’est une première pour un modèle de cette gamme tarifaire.
Du côté du raisonnement stratégique, le Vending-Bench Arena met les agents IA en compétition sur des stratégies business de distributeurs automatiques. Sonnet 4.6, surnommé « The Monopolist » par les organisateurs du benchmark, a généré environ 5 600 dollars de profit simulé, soit 1 600 dollars de plus que la version précédente. Ce type de benchmark illustre bien la polyvalence du modèle au-delà des simples tests académiques.

Sonnet 4.6 contre Opus 4.6 : où se situe la différence
Le tableau comparatif entre les deux modèles révèle un schéma clair. Sonnet 4.6 dépasse Opus sur les tâches bureautiques (GDPval), les agents financiers et le Terminal Bench CLI. Opus conserve son avance sur le raisonnement profond et complexe, là où sa capacité à décomposer des problèmes sophistiqués fait la différence.
En résumé, Sonnet gagne sur les tâches productives du quotidien tandis qu’Opus reste le choix incontournable pour le codage avancé et le raisonnement de haut niveau. Comme l’a récemment montré la recherche d’Anthropic sur le fonctionnement interne de ses modèles, la profondeur de raisonnement reste un axe de différenciation majeur entre les gammes.
Pour les développeurs et les équipes techniques, cela signifie concrètement que Sonnet 4.6 est pratiquement un Opus à moitié prix. La majorité des tâches quotidiennes, de la génération de code au traitement de documents, seront couvertes avec un niveau de qualité quasi identique. Opus reste pertinent pour les projets complexes nécessitant un raisonnement en profondeur.

Comment activer Claude Sonnet 4.6 et profiter du million de tokens
L’activation est immédiate. Sur claude.ai, Sonnet 4.6 est désormais le modèle par défaut pour tous les utilisateurs, qu’ils soient sur l’offre gratuite ou payante. Aucune manipulation n’est nécessaire : il suffit d’ouvrir une nouvelle conversation pour en bénéficier automatiquement.
Pour accéder à la fenêtre de contexte d’un million de tokens, il faut sélectionner le modèle spécifiquement dans les paramètres. Anthropic le traite comme un modèle distinct, ce qui permet de basculer entre la version standard et la version étendue selon les besoins de chaque projet.
Sur Claude Code, la mise à jour est automatique si l’outil est à jour. Sonnet 4.6 y est le modèle par défaut. Les nouvelles fonctionnalités incluent l’adaptive reasoning (présent depuis Opus 4), la compression de contexte pour optimiser l’utilisation des tokens, et la recherche web intégrée avec filtrage Python et connecteurs MCP pour Excel.
Que vous soyez développeur cherchant un outil de codage performant, professionnel ayant besoin d’automatiser des tâches bureautiques ou simplement curieux d’explorer les capacités de l’IA générative, Sonnet 4.6 représente aujourd’hui le meilleur point d’entrée dans l’écosystème Claude. Avec des performances qui chatouillent le haut de gamme pour un coût nul, la barrière à l’entrée n’a jamais été aussi basse.




0 Commentaires
Aucun commentaire pour le moment. Soyez le premier à commenter !