
Claude Managed Agents : la promesse d’Anthropic
Anthropic vient d’annoncer Claude Managed Agents, disponible en beta publique sur la Claude Platform. L’idée est simple : donner aux développeurs tout ce qu’il faut pour construire et déployer des agents IA à grande échelle, sans avoir à réinventer l’infrastructure à chaque projet.
Le produit combine un agent harness optimisé pour la performance avec une infrastructure de production prête à l’emploi. Concrètement, cela veut dire passer d’un prototype fonctionnel à un déploiement réel en quelques jours. Les premiers exemples montrent des pipelines multi-agents : un orchestrateur qui coordonne des agents spécialisés (analyste, rapporteur, forecaster), capables de traiter des tâches complexes sur plusieurs minutes et des dizaines de milliers de tokens.
C’est le signal qu’Anthropic passe d’une vision « modèle de langage » à une vision « plateforme d’agents opérationnels ». Pour mieux comprendre le contexte dans lequel cette annonce arrive, notre analyse sur la semaine IA la plus folle de mars 2026 donne un éclairage utile sur la cadence d’Anthropic.

Le vrai problème : tout ce qui entoure l’agent
Déployer un agent en production, c’est simple sur le papier. En pratique, les premières semaines ressemblent à ça : un dashboard VSCode avec trois sticky notes collées dessus, « FIX AUTHFLOW by next week », « Don’t forget to eat dinner », « Retry atom took about staging at dinner, retry needed ». Des notifications Sentry et CloudWatch qui clignotent en arrière-plan. Et toi qui jongles entre les bugs pendant que l’agent tourne… ou pas.
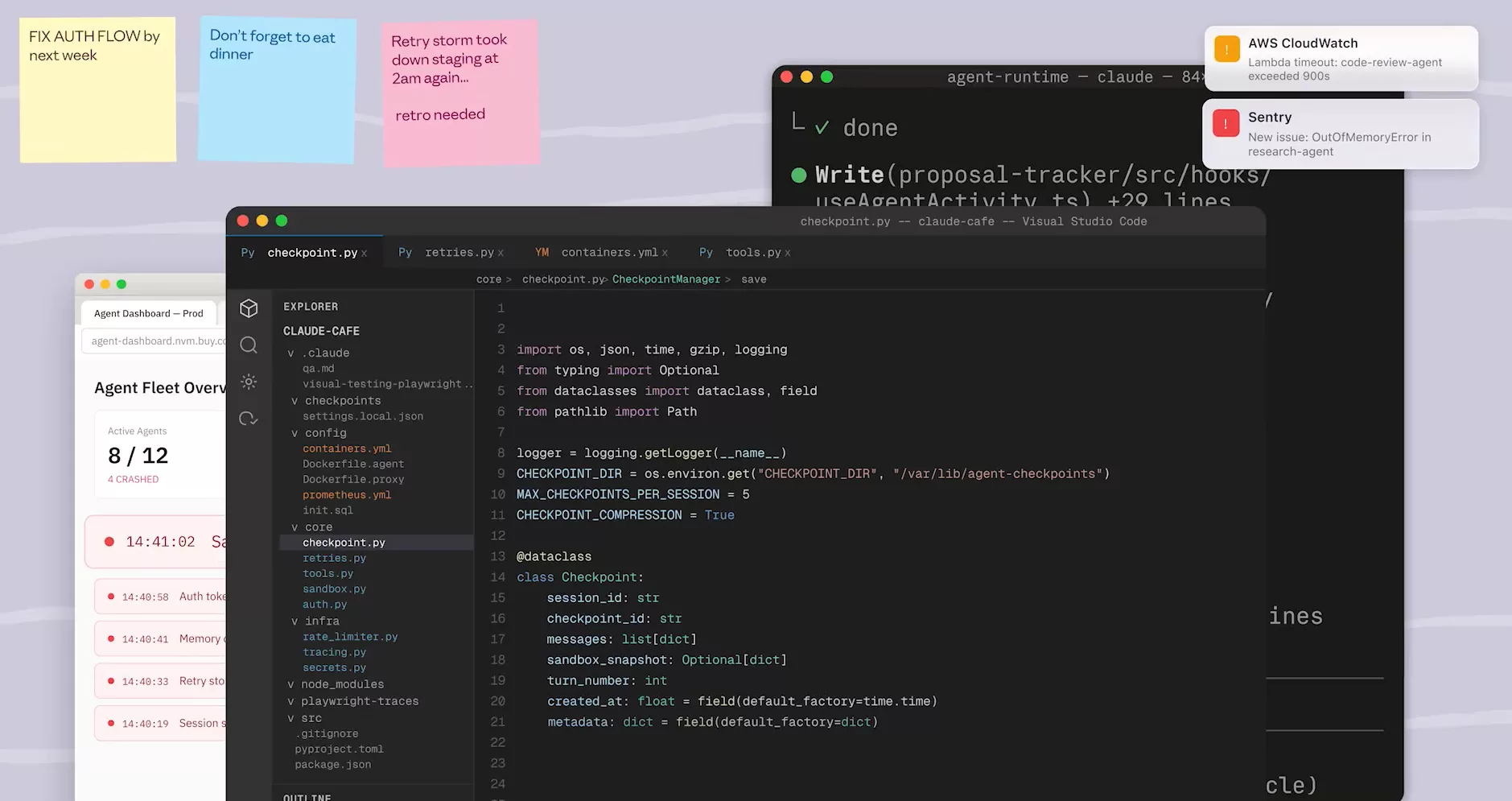
Les pannes sont rarement élégantes. Un web_search qui ne peut plus joindre api.search.brave.com : le circuit breaker accumule 10 ConnectionError consécutives, bascule en état OPEN, et les 3 tentatives de retry s’épuisent contre un upstream mort. Résultat : l’agent se bloque silencieusement. Ailleurs, un container sandbox tué par le kernel OOM killer, exit code 137, SIGKILL, parce que le step 0 recharge le state complet du modèle sans passer par le checkpoint incrémental. Ce ne sont pas des cas extrêmes. Ce sont les bugs de la semaine 2.
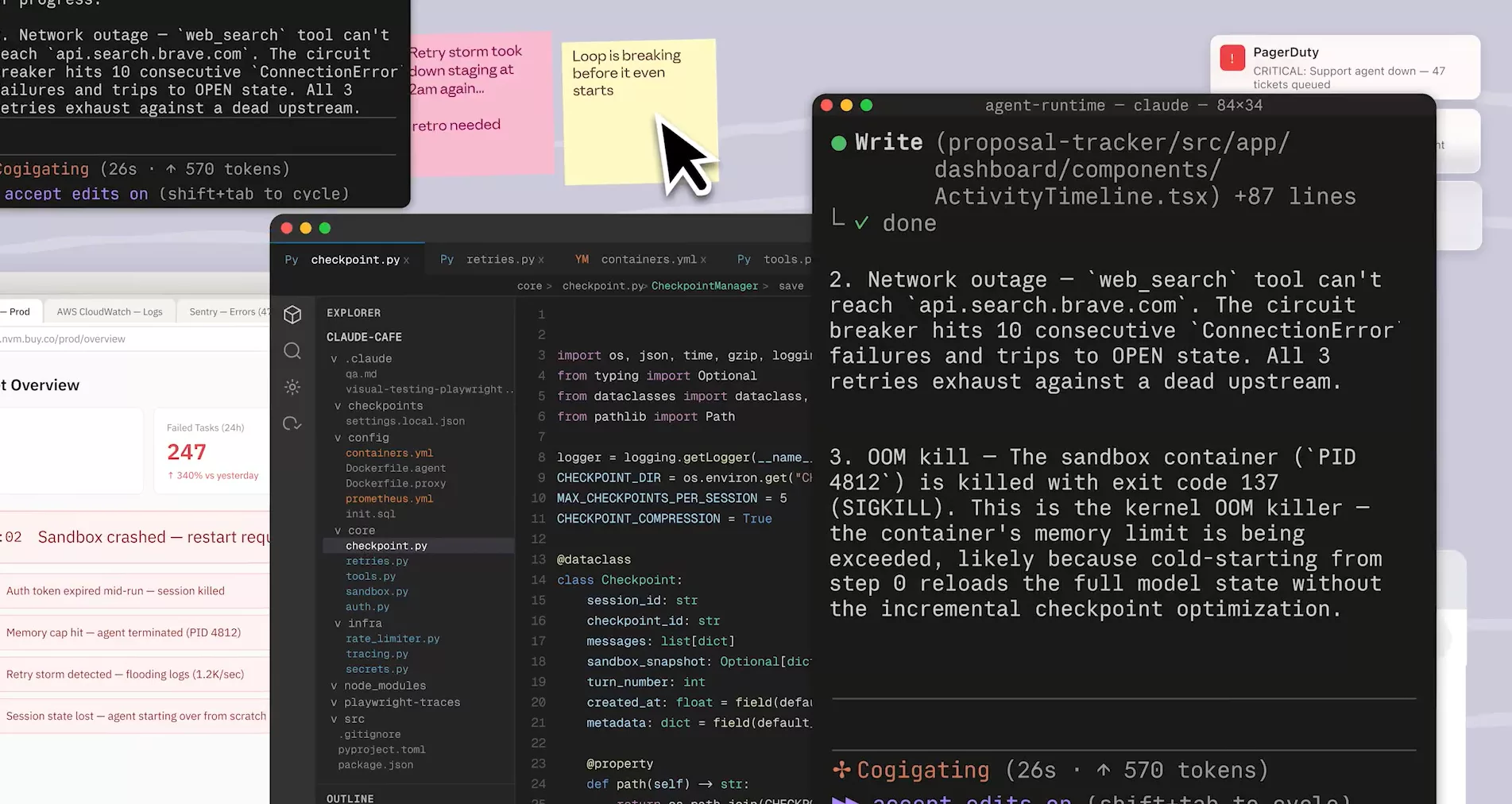
Le vrai problème n’est pas l’agent lui-même. C’est tout ce qui l’entoure : la gestion des retries, les circuit breakers, les limites mémoire, la récupération après crash, les secrets d’authentification à ne pas exposer, les logs à rendre lisibles. Chaque équipe réinvente ça de zéro. Ça prend des semaines, ça casse de façon imprévisible, et ça éloigne du seul truc qui compte : ce que l’agent est censé faire. C’est d’ailleurs dans ce contexte qu’on voit l’IA transformer en profondeur l’économie du développement logiciel.
8 couches d’infrastructure absorbées nativement
Vercel a fait ça pour le frontend. Lambda l’a fait pour le compute. Anthropic est en train de faire la même chose pour les agents IA : absorber toute la plomberie qui n’a aucune valeur ajoutée pour toi.
- Sandboxing : déjà disponible. L’agent tourne dans un environnement isolé. S’il plante ou fait n’importe quoi, ça reste confiné.
- Error recovery : quand un outil échoue, Claude ne laisse pas l’agent mourir. Il identifie l’erreur et tente une récupération propre.
- Auth : la gestion des tokens, des sessions et des accès API n’est plus ton problème. Claude s’en charge pour les outils connectés.
- Memory : l’agent retient ce qui s’est passé dans la session sans que tu aies à implémenter un système de contexte maison.
- Event state mgmt : si l’agent attend un événement externe (webhook, réponse utilisateur, résultat d’un outil lent), l’état est préservé. Pas de polling, pas de flag global à gérer.
- File persistence : les fichiers produits ou consommés pendant l’exécution sont stockés et accessibles entre les étapes, sans que tu montes un bucket S3 à la main.
- Checkpointing : si l’exécution s’arrête à mi-chemin, l’agent peut reprendre là où il en était. Fini les tâches longues qui repartent de zéro après un crash.
- Retry policies : les appels instables ou les timeouts sont relancés automatiquement selon des règles configurables. Tu ne réécris plus la même logique de backoff pour chaque projet.
Concrètement, ça représente plusieurs semaines de boulot que tu n’auras pas à faire. Et surtout, ce sont des composants que la plupart des équipes réimplémentent mal, trop vite, sous pression. Les avoir natifs dans la plateforme change vraiment la donne.

Les 8 couches d’infrastructure gérées nativement. Le sandboxing est déjà disponible, les 7 autres arrivent progressivement durant la beta.
Créer un agent en moins d’une minute
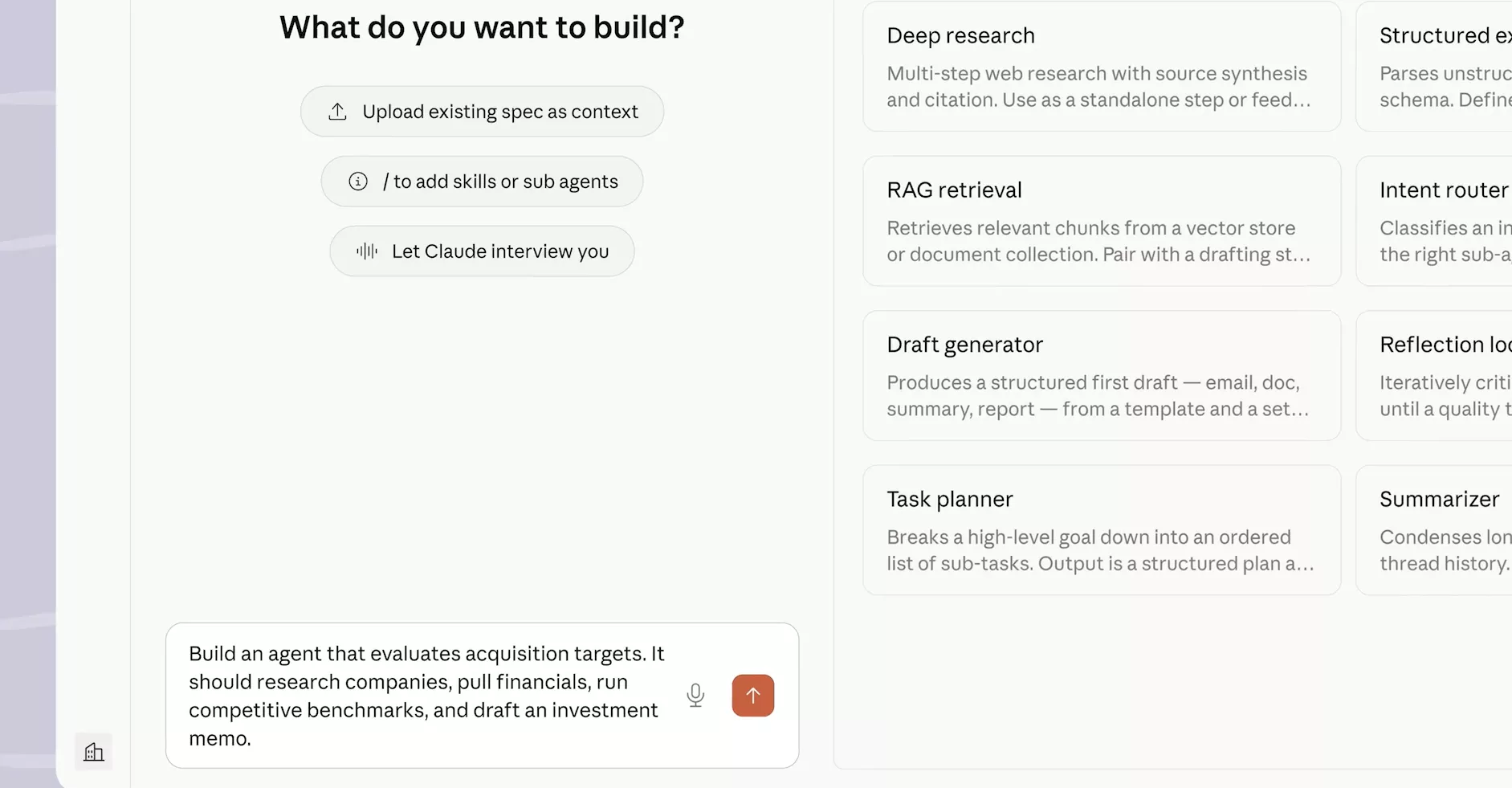
Créer un agent sur Claude Platform prend littéralement moins d’une minute. Une fois sur l’interface, une question simple s’affiche : « What do you want to build ? ». Trois chemins s’offrent à toi : importer une spec existante comme contexte, ajouter des compétences et sous-agents via la commande /, ou laisser Claude t’interviewer pour affiner ton besoin. Pour ceux qui préfèrent partir d’une base solide, six templates sont proposés directement : Deep research (recherche web multi-étapes avec synthèse et citations), RAG retrieval (interrogation de documents), Draft generator (rédaction d’emails, docs et rapports), Task planner (décomposition d’objectifs en sous-tâches), Intent router (classification et routage vers le bon sous-agent), et Summarizer (condensé avec historique de thread). Chaque template est un point de départ, pas une contrainte.
L’exemple affiché dans la zone de texte de l’interface illustre parfaitement ce que la plateforme sait faire : « Build an agent that evaluates acquisition targets. It should research companies, pull financials, run competitive benchmarks, and draft an investment memo. » Une instruction en langage naturel, et l’agent sait qu’il devra coordonner de la recherche, de l’analyse financière, de la comparaison concurrentielle et de la rédaction.
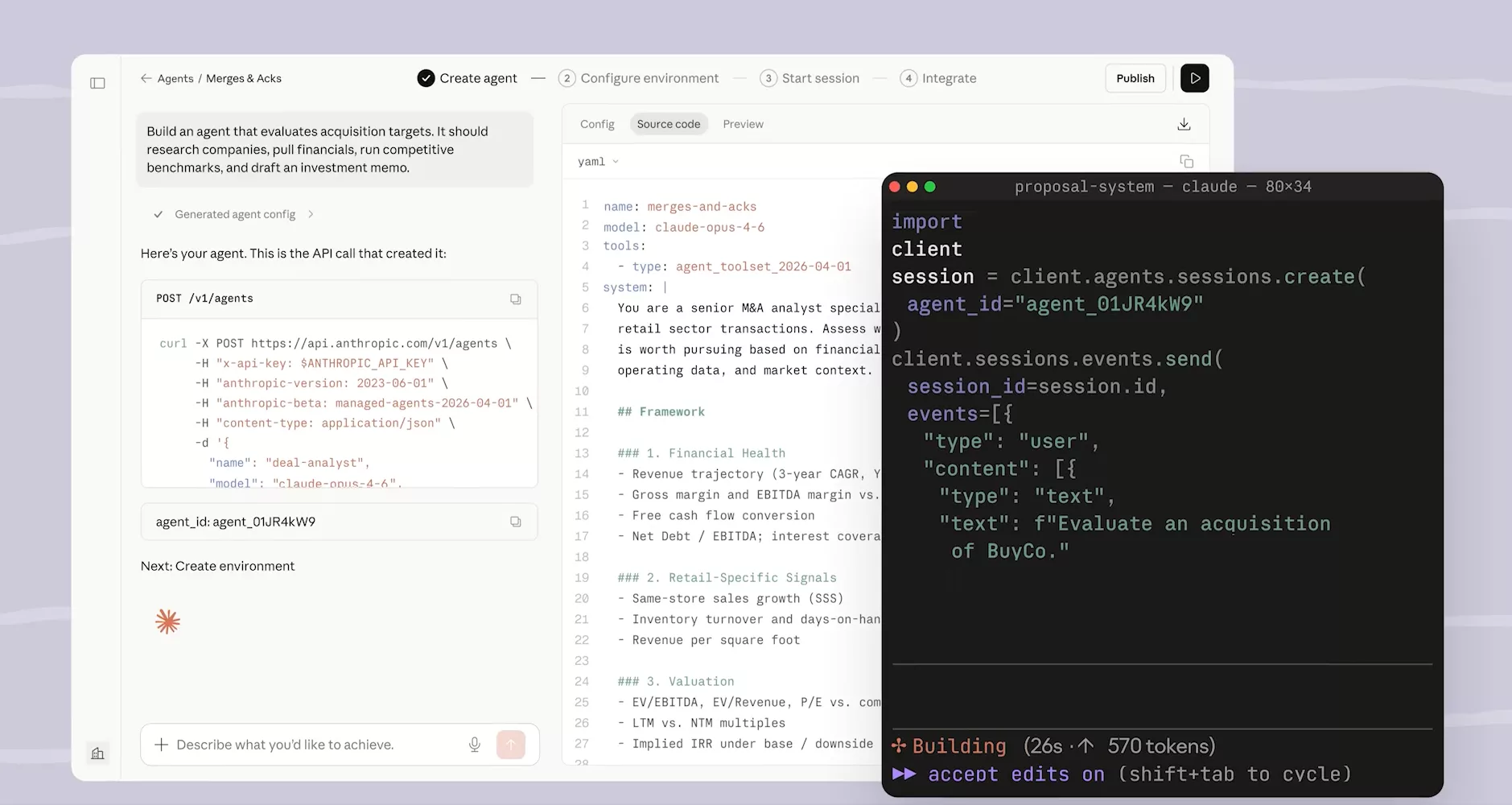
Cas concret : un agent M&A analyst en 4 lignes
Prenons un cas concret pour voir ce que ça donne en pratique. L’image montre un agent configuré pour évaluer des cibles d’acquisition : on lui donne l’instruction de rechercher des entreprises, récupérer leurs données financières, faire des benchmarks compétitifs, et rédiger un memo d’investissement. Le lancer via l’API Python tient en 4 lignes, une session créée avec client.agents.sessions.create(agent_id="agent_01JR84K9..."), puis un événement envoyé avec sessions.send() contenant le texte « Evaluate an acquisition of BuyComp ». C’est tout côté client. Ce qui se passe derrière est une autre histoire.
L’agent charge automatiquement 8 fichiers CSV : bilans financiers FY2023-2025, cash flows, performance par région, métriques inventaire Q4 2025, planning des baux, démographie clients, plus un PDF de présentation management. En 5 minutes 34 secondes, le système multi-agents s’organise en quatre rôles distincts, Orchestrator, Reporter, Analyst, Forecaster, chacun traitant une partie du dossier en parallèle. Le résultat : Revenue $429M, EBITDA $59M, Net Debt $124M, avec 71 000 tokens traités côté entrée. Le system prompt de l’agent Analyst est explicite : « You are a senior M&A analyst specializing in retail sector transactions » avec un framework structuré autour du CAGR 3 ans, des tendances YoY et des signaux spécifiques au retail.
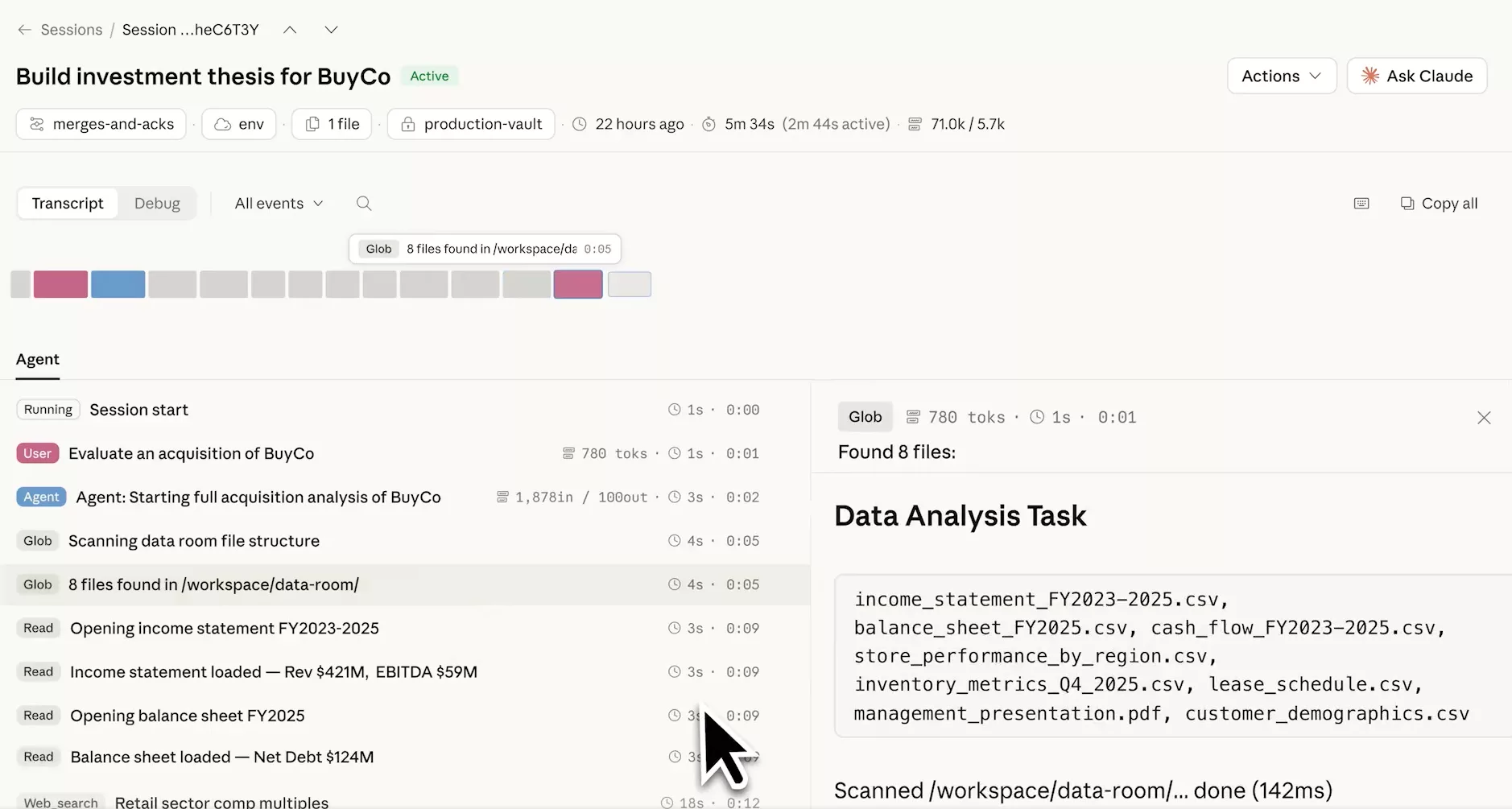
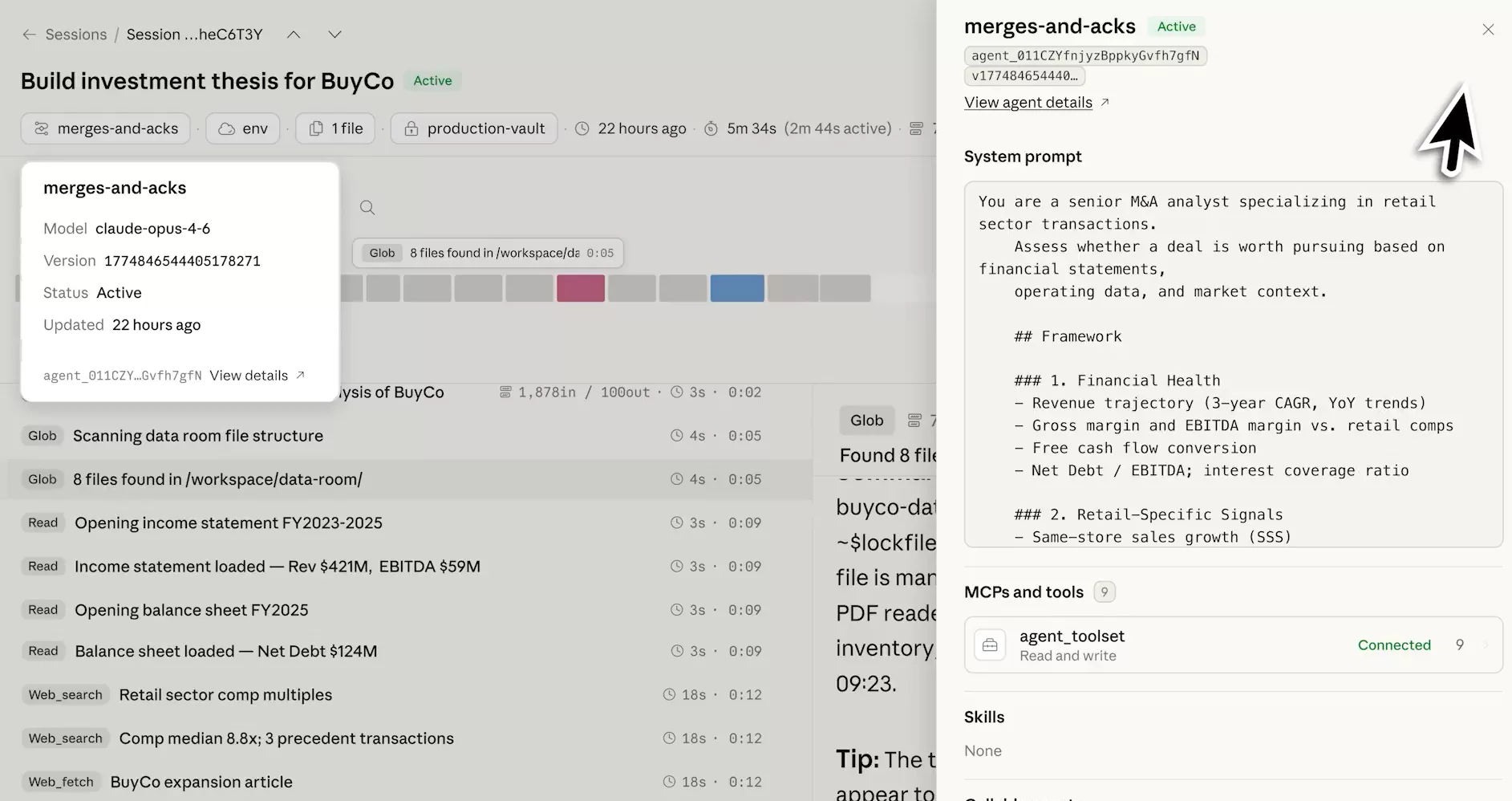
Ce qui est intéressant ici, c’est moins la prouesse technique que l’architecture de délégation. L’Orchestrator ne fait pas tout lui-même : il coordonne des sous-agents spécialisés qui tournent en parallèle, chacun avec ses outils connectés (agent_toolset Connected). Le temps actif réel est de 2 minutes 44 secondes sur les 5m34s de session, ce qui donne une idée du gain par rapport à une analyse séquentielle classique. Pour un développeur qui veut automatiser des workflows analytiques lourds, le modèle est clair : définir le rôle dans le system prompt, brancher les fichiers, laisser l’architecture multi-agents gérer la parallélisation.
Ce que ça change face à la concurrence
Le marché des agents IA en production est encombré : OpenAI propose ses Assistants API, Google pousse Vertex AI Agent Builder, et les frameworks open-source comme LangChain ou CrewAI ont leurs communautés actives. Ce que Claude Managed Agents tente de faire différemment, c’est d’absorber les 8 couches d’infrastructure qui freinent habituellement le passage du prototype au déploiement, et de les exposer via une interface unique plutôt que de laisser chaque équipe les reconstruire. Le pari est lisible : réduire le temps entre « ça marche en local » et « ça tourne en prod » de semaines à quelques jours.
La plateforme est accessible dès maintenant depuis le tableau de bord développeur sur claude.ai. Les sessions de monitoring sont déjà fonctionnelles, la timeline de progression des agents est visible en temps réel, et les modèles Opus, Sonnet et Haiku sont sélectionnables selon le rapport coût/performance recherché. Ce qui sera déterminant à mesure que la plateforme sort de beta, c’est la maturité des outils de débogage et la granularité du contrôle sur les politiques de sécurité : deux points que les équipes en production surveilleront de près avant de committer leurs workflows critiques. Pour suivre les prochaines annonces d’Anthropic, notre article sur les deux fuites majeures en 5 jours illustre bien la cadence d’une entreprise qui avance vite.






0 Commentaires
Aucun commentaire pour le moment. Soyez le premier à commenter !