
Anthropic just dropped Claude Opus 4.7 benchmarks, and the roadmap is finally on the table. After weeks of rumors and early traces spotted in the code, the model arrives with a full scorecard facing GPT-5.4, Gemini 3.1 Pro, and above all Mythos — the internal version that has been the talk of the industry since the Mythos leak at the end of March. Claude Opus 4.7 lands in a competitive landscape that has never moved this fast.
The verdict fits in one sentence. Claude Opus 4.7 is not a revolution — it is a calculated half-step. Sitting exactly halfway between Opus 4.6 and Mythos, too precisely positioned to be a coincidence. And that tells you a great deal about Anthropic’s strategy in 2026.
Claude Opus 4.7 benchmarks: a calibrated half-step toward Mythos
The first thing that jumps out when you look at the Claude Opus 4.7 benchmarks is the unsettling regularity of the gaps. On almost every benchmark, the improvement between Opus 4.6 and Claude Opus 4.7 lands at exactly 50% of the gap between Opus 4.6 and Mythos. Mathematically. The numbers line up too neatly to be accidental.
The most credible hypothesis is that Claude Opus 4.7 is a distilled version of Mythos. A model that has been deliberately blunted to run faster, on more accessible hardware, and above all without triggering the cold sweats that Mythos caused internally at Anthropic.
Mythos, let’s remember, is the internal model that more or less hacked the entire internet during a demo a week and a half ago. Anthropic privately described it as « nuclear in the hands of a child. » To put it simply, they are in no rush to hand it to everyone. Claude Opus 4.7 is the commercial compromise between « we can’t release anything » and « we have to move before GPT-5.5. »
The benchmarks that explode: coding, reasoning, vision
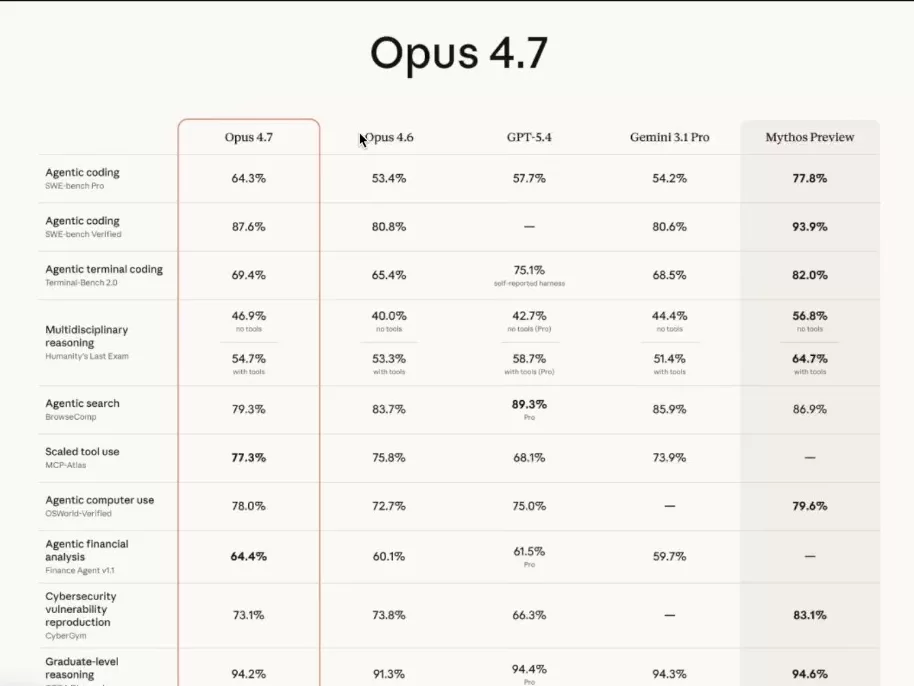
Let’s start with the flagship benchmark: SWE-bench Pro. Opus 4.6 was capped at 53.4%. Claude Opus 4.7 climbs to 64.3%. More than ten points gained on the most-watched task in the industry — the one that measures a model’s real ability to write production software in an agentic context. Mythos, for reference, sits at 77.8%.
The same dynamic plays out on SWE-bench Verified, which jumps from 80.8 to 87.6%. Graduate-level reasoning, measured on GPQA Diamond, rises to 94.2%. At this point, the model outperforms the majority of science master’s graduates on their own questions. And it does so in parallel, across thousands of instances, at a speed that bears no resemblance to a human brain.
The most spectacular leap is arguably visual reasoning on CharXiv. Without tools, Opus 4.6 lagged at 69.1%. Claude Opus 4.7 jumps to 82.1%. With tools, the figure climbs to 91%. That is the equivalent of going from decent vision to near-perfect sight. For every application that reads charts, diagrams, or screenshots, this is a scale change.
Humanity’s Last Exam follows the same logic. Opus 4.6 was at 40% without tools; Claude Opus 4.7 reaches 46.9%. Mythos sits at 56.8. We are still far from 100%, but on this kind of benchmark, reaching 50% is actually close to saturation. The learning curve is not linear — it flattens sharply on the final percentage points.
When Claude Opus 4.7 steps back deliberately: the scores that drop
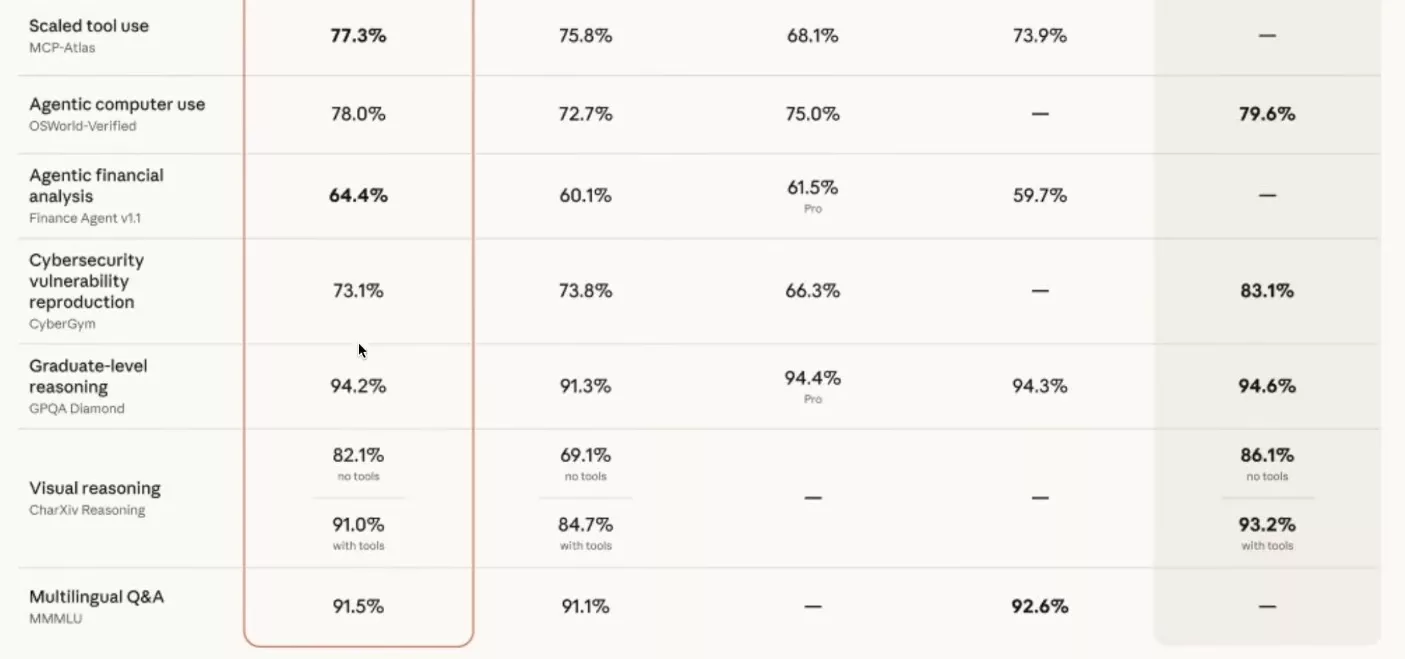
This is where the scorecard gets truly interesting. Claude Opus 4.7 is not better everywhere. On two specific benchmarks, it regresses compared to Opus 4.6. And this is clearly not a side effect.
The first is Agentic Search on BrowseComp. Opus 4.6 scored 83.7%. Claude Opus 4.7 drops to 79.3%. Four points lost on the model’s ability to navigate and extract information from the web autonomously. The second is cybersecurity vulnerability reproduction on CyberGym. Opus 4.6 was at 73.8%; Claude Opus 4.7 falls to 73.1%. Marginal, but moving in the wrong direction.
The common thread between these two benchmarks is obvious. They are exactly the two capabilities that worry Anthropic’s safety teams the most. A model that excels at browsing the web on its own and knows how to reproduce known vulnerabilities is the recipe for a formidable offensive tool. The throttling is almost certainly intentional, and it is done with a scalpel.
Terminal coding also shows a more modest jump. It goes from 65.4 to 69.4%, while Mythos sits at 82%. Manipulating a terminal is exactly the vector that transforms a chatty model into an agent capable of exfiltrating data or modifying a system. This deliberate slowdown is not a bug — it is the feature.
Mythos in the background: why Anthropic keeps its strongest model back
The full scorecard tells a very coherent story. Claude Opus 4.7 is the commercial version of Mythos, calibrated to preserve the competitive edge without unlocking the capabilities deemed too dangerous. Anthropic sells general intelligence — not digital weapons.
This strategy stands in sharp contrast to the benchmark race that most competitors run. OpenAI and Google tend to push every score forward without communicating much about internal guardrails. Anthropic plays the opposite game. They publicly acknowledge that certain capabilities are removed from the public model. Claude Opus 4.7 is Mythos with the sharp edges filed off.
This logic also connects to what we have been observing for several months in the Claude ecosystem, notably with the launch of Managed Agents in public beta. The goal is no longer to shock with raw capabilities, but to deliver a stable building block that can be integrated without running into an execution refusal every three requests.
That said, you can hold a nuanced view of this policy. Keeping a more powerful model internal raises real questions about the distribution of power. A handful of engineers at a Californian company have access to Mythos. The rest of the world makes do with the half-strength version. If Mythos is truly as capable as Anthropic implies, the question is no longer technical — it is political.
What Claude Opus 4.7 actually changes for you (and what it doesn’t)
Let’s be direct. If you have infrastructure running cleanly on Opus 4.6, there is no urgency to migrate everything to Claude Opus 4.7. The API endpoints are identical, the migration is trivial, but the practical gain on your real use cases will probably be marginal.
The trap of 2026 is model commoditization. You see many developers jumping from Opus 4.6 to GPT-5.4 to pick up three or four percent on a specific benchmark, then reworking all of their prompt configuration, scaffolding, and tests. The time invested in that migration far exceeds the actual gain — a phenomenon we analyzed in depth at the time of the GPT-5.4 release.
What hasn’t changed since 2020 is the real inflection point. The zero-to-one moment was GPT-3 enabling the conversion of a natural language request into an executable command. Since then, we have been stacking horizontal improvements. Claude Opus 4.7 is one of them. It reduces how much scaffolding you need to build, but it does not unlock a fundamentally new category of use case.
The right read is this: AI doesn’t make things possible — it makes them profitable. What wasn’t cost-effective to automate two years ago is today. From hyper-personalized marketing targeting to large-scale financial analysis, the field of profitable use cases expands with every generation. But the nature of the terrain itself stays the same.
My advice for the weeks ahead: test Claude Opus 4.7 on your three or four critical use cases, compare the costs and latency, and if the qualitative gain is meaningful, migrate. Otherwise, keep your stack and focus your energy on the scaffolding around the model rather than chasing scorecard numbers. Spud, the next OpenAI model, should drop within days. The circus goes on.





0 Commentaires
Aucun commentaire pour le moment. Soyez le premier à commenter !