
Source vidéo
BridgeMind — I Spent 200 Million Tokens Vibe Coding With Gemini 3.1 Pro
Chaîne YouTube BridgeMind · 24 min · Février 2026
214,6 millions de tokens. 17 heures de travail intensif. C’est ce qu’il a fallu à la chaîne YouTube BridgeMind — une communauté de 70 000 vibe coders — pour mettre Gemini 3.1 Pro à l’épreuve dans des conditions de production réelles. Pas de tests artificiels, pas de prompts académiques : 17 heures à refactoriser un vrai site web, déboguer un système d’authentification, créer des vidéos marketing et animer des interfaces. Le verdict est sans appel, et il va surprendre beaucoup de ceux qui avaient tiré un trait sur les modèles Google.
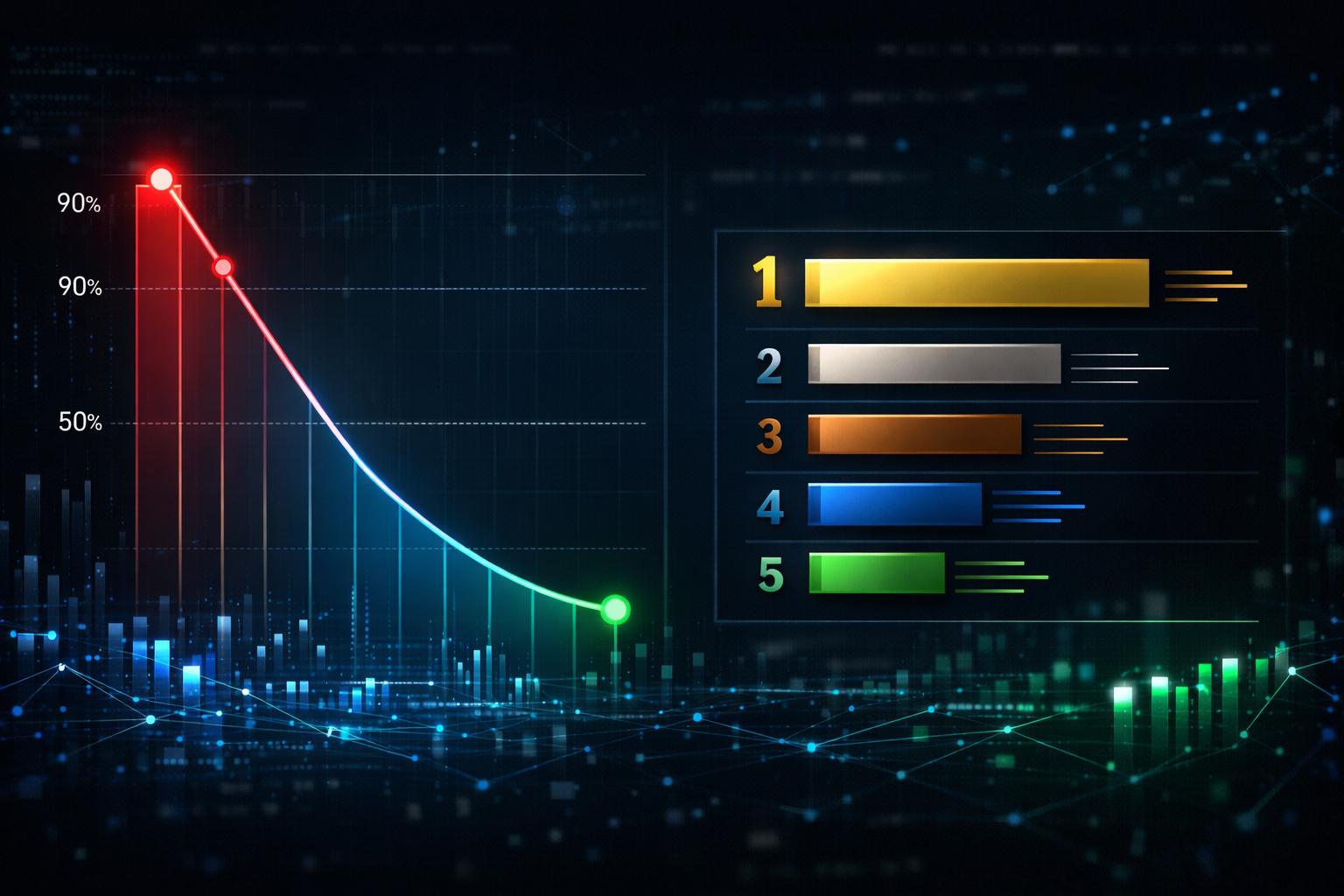
Les benchmarks qui changent vraiment la donne
Les chiffres sont déjà connus depuis le lancement officiel : ARC-AGI-2 à 77,1 % (contre 31,1 % pour Gemini 3 Pro), SWE-bench en forte progression, Live Code Bench passant de 2 439 à 2 887. Mais BridgeMind met en lumière deux métriques particulièrement significatives que l’annonce officielle a moins mis en avant.
Premier point : l’indice de codage d’Artificial Analysis. Gemini 3.1 Pro y décroche la première place avec un score de 56, devant Claude Opus 4.6 à 48 et GPT-5 à 49. C’est ce classement-là — spécifiquement axé sur le code — qui devrait interpeller les développeurs plus que les benchmarks de raisonnement général.
Second point, encore plus parlant : le taux d’hallucinations. Sur le benchmark AA-Omniscience (Knowledge and Hallucination), Gemini 3.1 Pro atteint 50 %, soit le taux le plus bas parmi tous les modèles frontier actuels. Claude Opus 4.5 affichait 58 %, GPT-5.2 grimpe à 78 %, et la version précédente de Gemini plafonnait à 88 %. C’est là que réside peut-être la plus grande amélioration : un modèle qui suit mieux vos instructions et dévie moins sur des chemins non désirés.

UI et styling : il remplace désormais Opus 4.6
La première chose que BridgeMind a testée est le refactoring de son propre site web — 20 à 30 pages entièrement reprises par Gemini 3.1 Pro. Le résultat est éloquent. Animations 3.js pour illustrer les capacités de la plateforme, composants UI uniques avec les logos réels des outils intégrés (Cursor, Claude, Windsurf, etc.), vidéos marketing générées avec Remotion, copywriting intégral dans la voix de la marque via une « copywriting skill » personnalisée dans Cursor.
Une démonstration particulièrement frappante : la génération d’animations 3.js représentant le fonctionnement de 16 agents en parallèle, avec compression vidéo automatique pour améliorer les performances du site. Pour le design d’interface, le verdict de BridgeMind est sans équivoque : « Je ne vais plus jamais utiliser Opus 4.6 pour le styling. C’est désormais le modèle de référence pour ça. » Gemini 3 Pro était déjà bon sur le styling — 3.1 Pro est une marche au-dessus, nettement visible à l’œil nu.

Backend : il a résolu ce qu’Opus 4.6 n’a pas pu faire
C’est probablement l’anecdote la plus intéressante du test. Il était 1h du matin. BridgeMind bataillait avec un bug complexe dans son système d’authentification OAuth. Opus 4.6 avait été sollicité, relancé, alimenté avec tous les éléments de contexte disponibles. Résultat : aucune solution.
Le même problème est alors soumis à Gemini 3.1 Pro, en mode « plan » dans Cursor. Le modèle génère un plan de refactorisation, l’utilisateur valide et lance l’exécution. Le résultat : le système OAuth est entièrement refondu — côté API, application web principale, portail admin et interface utilisateur — soit quatre dépôts distincts, traitant simultanément la logique backend, le front-end et les auth guards complexes. En un seul shot, là où Opus 4.6 avait échoué à plusieurs reprises.
Pour BridgeMind, c’est ce genre d’exemple qui illustre mieux les capacités réelles d’un modèle que n’importe quel benchmark — et c’est directement en lien avec la réduction du taux d’hallucinations : le modèle a compris l’instruction sans dériver, a suivi le plan sans improviser, et a livré ce qui était demandé.

Coût et vitesse : l’argument décisif face à la concurrence
Après 17 heures et 214,6 millions de tokens, la question du coût est particulièrement concrète. Gemini 3.1 Pro est facturé 2 dollars par million de tokens en entrée et 12 dollars en sortie. Claude Opus 4.6 est à 5 et 25 dollars respectivement. En termes de rapport qualité-prix, la différence est massive — d’autant plus quand les performances sur les tâches testées sont au moins équivalentes, voire supérieures sur certains points.
La vitesse est également un facteur notable. Sur Google Vertex, Gemini 3.1 Pro tourne à 60 tokens par seconde, contre 42 pour Sonnet 4.6, soit environ 50 % plus rapide. Sur Artificial Analysis, le modèle affiche 106 points contre 73 pour Opus 4.6. Cette vitesse est perceptible dans les workflows de vibe coding : les boucles d’édition-test-correction sont plus fluides, les itérations plus rapides, et la productivité globale s’en ressent directement sur une session de 17 heures.
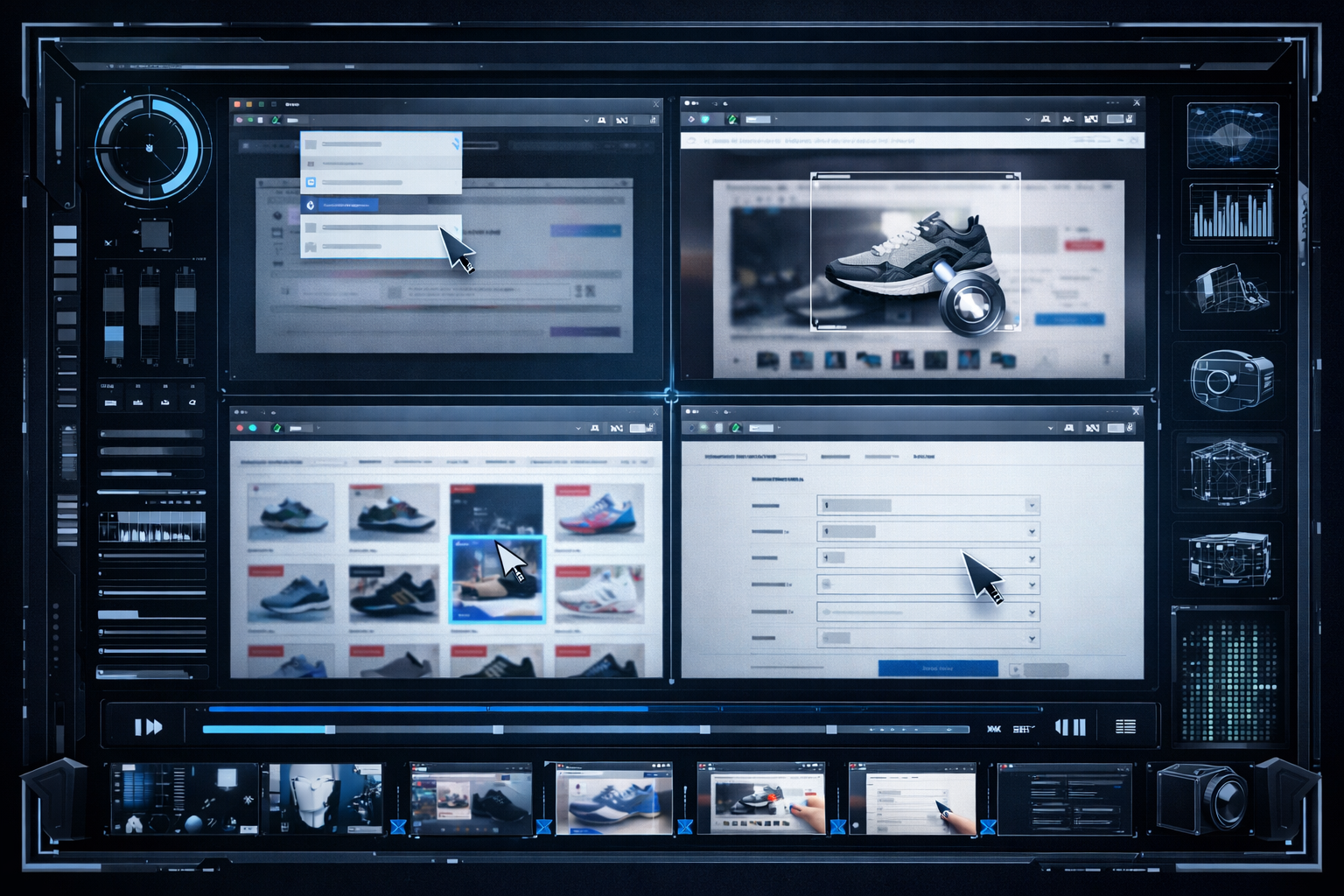
Anti-gravity : l’outil Google à ne plus ignorer
La seconde partie du test porte sur Anti-gravity, l’environnement d’agents natif de Google. BridgeMind admet ouvertement ne pas l’avoir utilisé depuis des mois en raison de résultats inconsistants. La version actuelle, associée à Gemini 3.1 Pro, change la donne.
La fonctionnalité qui impressionne le plus : le browser use natif. Contrairement à Cursor qui utilise Playwright avec des outils de navigation limités, Anti-gravity est capable de prendre des screenshots du navigateur, d’enregistrer des vidéos de navigation, de cliquer et faire défiler des pages, d’évaluer le DOM en temps réel et de tester des flows d’authentification complets. Pour un développeur, cela signifie qu’un agent peut non seulement lire votre code, mais littéralement naviguer sur votre site et constater ce qui ne fonctionne pas.
Lors du test, cinq agents Anti-gravity ont été lancés en parallèle : refactoring UI blog, audit des erreurs console via Chrome DevTools MCP, review sécurité de l’API NestJS, amélioration des thèmes sur deux applications Tauri, et suppression d’une fonctionnalité de drag-and-drop défectueuse. Le bilan : « Si vous voulez le meilleur de Gemini, utilisez Anti-gravity ou le Gemini CLI — c’est leur environnement natif, comme Claude Code l’est pour Anthropic. » À noter toutefois : Gemini 3.1 Pro n’est pas encore disponible dans le Gemini CLI au moment du test — uniquement dans Anti-gravity et via l’API. La communauté BridgeMind a accordé son « stamp of approval » au modèle, une distinction réservée à un nombre très limité de modèles, et compte l’intégrer durablement dans son workflow de vibe coding.





0 Commentaires
Aucun commentaire pour le moment. Soyez le premier à commenter !