
Anthropic vient de lâcher Claude Opus 4.7, et la feuille de route est enfin posée sur la table. Après des semaines de rumeurs et de premières traces repérées dans le code, le modèle débarque avec un scorecard complet face à GPT-5.4, Gemini 3.1 Pro et surtout Mythos, la version interne dont on parle depuis la fuite Mythos de fin mars.
Le verdict tient en une phrase. Opus 4.7 n’est pas une révolution, c’est un demi-pas calculé. Exactement à mi-chemin entre Opus 4.6 et Mythos, trop dosé pour être un hasard. Et ça raconte beaucoup de choses sur la stratégie Anthropic en 2026.
Opus 4.7 débarque : un demi-pas calibré vers Mythos
La première chose qui saute aux yeux quand on regarde le scorecard, c’est la régularité troublante des écarts. Sur presque chaque benchmark, l’amélioration entre Opus 4.6 et Opus 4.7 fait pile 50% de l’écart entre Opus 4.6 et Mythos. Mathématiquement. Les chiffres collent trop bien pour que ce soit accidentel.
L’hypothèse la plus crédible, c’est qu’Opus 4.7 est une version distillée de Mythos. Un modèle qu’on a volontairement émoussé pour qu’il tourne plus vite, sur du hardware plus accessible, et surtout sans déclencher les sueurs froides qu’a provoqué Mythos en interne chez Anthropic.
Mythos, rappelons-le, c’est le modèle interne qui a piraté plus ou moins tout internet pendant une démo il y a une semaine et demie. Anthropic l’a qualifié en privé de « nucléaire entre les mains d’un enfant ». Autant dire qu’ils ne sont pas pressés de le refourguer à tout le monde. Opus 4.7, c’est le compromis commercial entre « on ne peut rien sortir » et « on doit bouger avant GPT-5.5 ».
Les benchmarks qui explosent : coding, raisonnement, vision
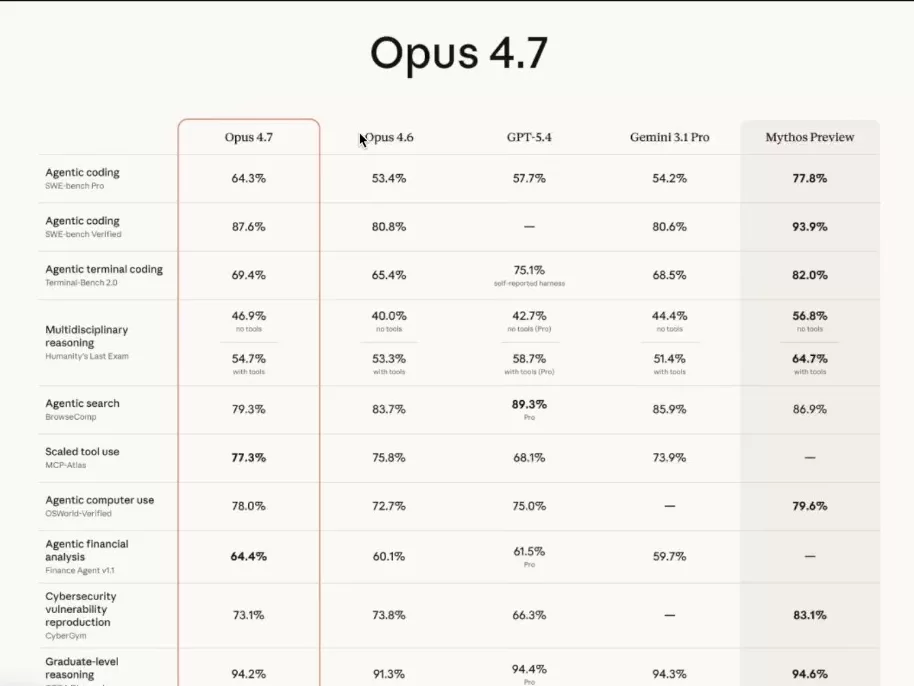
Commençons par le benchmark phare, le SWE-bench Pro. Opus 4.6 plafonnait à 53,4%. Opus 4.7 grimpe à 64,3%. Plus de dix points gagnés sur la tâche la plus scrutée de l’industrie, celle qui mesure la vraie capacité d’un modèle à coder du logiciel en contexte agentique. Mythos, pour référence, tape à 77,8%.
Même dynamique sur SWE-bench Verified qui passe de 80,8 à 87,6%. Le raisonnement de niveau graduate, mesuré sur GPQA Diamond, grimpe à 94,2%. À ce stade, le modèle bat la majorité des titulaires d’un master scientifique sur leurs propres questions. Et il le fait en parallèle, sur des milliers d’instances, à une vitesse qui n’a plus rien à voir avec un cerveau humain.
Le saut le plus spectaculaire, c’est sans doute le raisonnement visuel sur CharXiv. Sans outils, Opus 4.6 traînait à 69,1%. Opus 4.7 bondit à 82,1%. Avec outils, on grimpe à 91%. C’est l’équivalent de passer d’une vision correcte à une vue quasi parfaite. Pour toutes les applications qui lisent des graphiques, des diagrammes ou des captures d’écran, c’est un changement d’échelle.
Humanity’s Last Exam suit la même logique. Opus 4.6 était à 40% sans outils, Opus 4.7 monte à 46,9%. Mythos tape 56,8. On reste loin du 100%, mais sur ce genre de benchmark, atteindre 50%, c’est en réalité être déjà proche de la saturation. La courbe d’apprentissage n’est pas linéaire, elle se tasse violemment sur les dernières pour cent.
Quand Opus 4.7 recule volontairement : les scores qui chutent
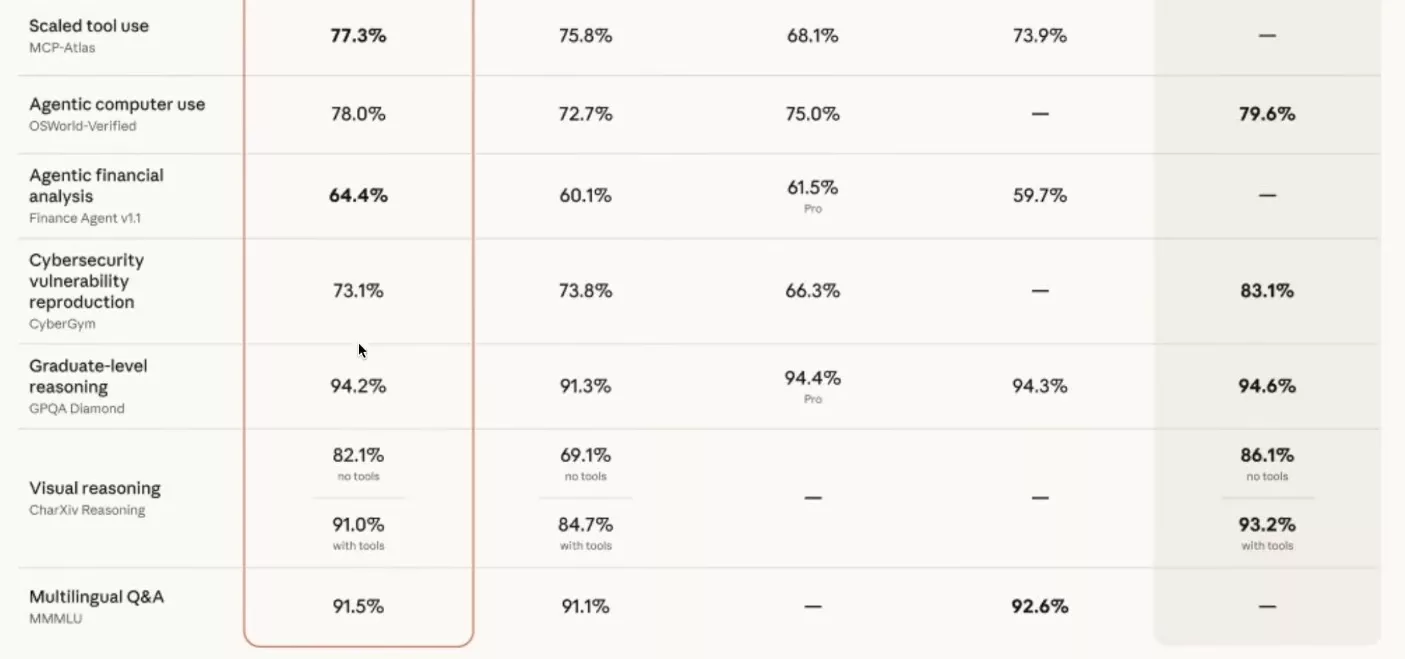
C’est là que le scorecard devient vraiment intéressant. Opus 4.7 n’est pas meilleur partout. Sur deux benchmarks précis, il recule par rapport à Opus 4.6. Et ce n’est clairement pas un accident de parcours.
Le premier, c’est l’Agentic Search sur BrowseComp. Opus 4.6 affichait 83,7%. Opus 4.7 tombe à 79,3%. Quatre points perdus sur la capacité du modèle à naviguer et extraire de l’information du web de manière autonome. Le second, c’est la reproduction de vulnérabilités cybersécurité sur CyberGym. Opus 4.6 était à 73,8%. Opus 4.7 descend à 73,1%. Léger, mais dans le mauvais sens.
Le point commun entre ces deux benchmarks saute aux yeux. Ce sont exactement les deux capacités qui inquiètent le plus les équipes de sécurité d’Anthropic. Un modèle qui excelle à fouiller le web tout seul et qui sait reproduire des vulnérabilités connues, c’est la recette d’un outil offensif redoutable. Le bridage est probablement volontaire, et il est fait à la lame.
Sur le terminal coding, le saut reste aussi plus modeste. On passe de 65,4 à 69,4%, alors que Mythos trône à 82%. Manipuler un terminal, c’est exactement le vecteur qui transforme un modèle bavard en agent capable d’exfiltrer des données ou de modifier un système. Ce ralentissement volontaire n’est pas un bug, c’est la feature.
Mythos en coulisse : pourquoi Anthropic garde le plus fort
Le scorecard complet raconte une histoire très cohérente. Opus 4.7 est la version commerciale de Mythos, calibrée pour garder l’avantage compétitif sans débloquer les capacités jugées trop dangereuses. Anthropic vend de l’intelligence générale, pas des armes numériques.
Cette stratégie tranche avec la course au benchmark que pratiquent la plupart des concurrents. OpenAI et Google ont tendance à pousser tous les scores en avant sans trop communiquer sur les garde-fous internes. Anthropic joue le contraire. Ils assument publiquement que certaines capacités sont retirées du modèle public. Opus 4.7, c’est du Mythos moins les angles coupants.
Cette logique recoupe d’ailleurs ce qu’on observe depuis plusieurs mois dans l’écosystème Claude, notamment avec le lancement des Managed Agents en beta publique. L’objectif n’est plus de choquer avec des capacités brutes, mais d’offrir une brique stable qu’on peut intégrer sans se prendre un refus d’exécution toutes les trois requêtes.
Reste qu’on peut avoir un avis nuancé sur cette politique. Garder un modèle plus puissant en interne pose de vraies questions de distribution du pouvoir. Quelques ingénieurs dans une boîte californienne ont accès à Mythos. Le reste du monde se contente de la version demi-tarif. Si Mythos est vraiment aussi capable qu’Anthropic le laisse entendre, la question n’est plus technique, elle est politique.
Ce que ça change vraiment pour vous (et ce qui ne change pas)
Soyons directs. Si vous avez une infrastructure qui tourne correctement sur Opus 4.6, il n’y a aucune urgence à tout basculer sur Opus 4.7. Les endpoints API sont identiques, la migration est triviale, mais le gain pratique sur vos vrais cas d’usage sera probablement marginal.
Le piège de 2026, c’est la commoditisation des modèles. On voit beaucoup de développeurs sauter d’Opus 4.6 à GPT-5.4 pour grappiller trois ou quatre pour cent sur un benchmark précis, puis se retaper toute la configuration du prompt, du scaffolding, des tests. Le temps investi dans cette migration dépasse largement le gain effectif. Un phénomène qu’on avait d’ailleurs analysé au moment de la sortie de GPT-5.4.
Ce qui n’a pas changé depuis 2020, c’est la vraie bascule. Le moment zéro-à-un, c’était GPT-3 qui permettait de convertir une requête en langage naturel en commande exécutable. Depuis, on empile des améliorations horizontales. Opus 4.7 en est une. Elle vous évite de construire autant de scaffolding qu’avant, mais elle ne débloque pas de cas d’usage fondamentalement neuf.
La bonne lecture, c’est celle-ci. L’IA ne rend pas les choses possibles, elle les rend profitables. Ce qui n’était pas rentable à automatiser il y a deux ans l’est aujourd’hui. Du ciblage marketing ultra-personnalisé à l’analyse financière de masse, le champ des usages rentables s’élargit à chaque génération. Mais la nature du terrain, elle, reste la même.
Mon conseil pour les semaines qui viennent. Testez Opus 4.7 sur vos trois ou quatre cas d’usage critiques, comparez les coûts et la latence, et si le gain qualitatif est sensible, migrez. Sinon, gardez votre stack, et concentrez votre énergie sur le scaffolding autour du modèle plutôt que sur la chasse aux chiffres du scorecard. Spud, le prochain modèle OpenAI, devrait tomber dans quelques jours. Le cirque continue.






0 Commentaires
Aucun commentaire pour le moment. Soyez le premier à commenter !